

Az előző bejegyzésben megmutattam, hogy lehet felépíteni egy TCP-kapcsolatot, most megmutatom, hogyan lehet kommunikálni a csatornán. A hivatalos dokumentáció és a Denzelii fórumtárs által mutatott hivatalos fejlesztői blog is elég hosszú kódrészleteket mutat, de mégis vannak fontos momentumok, amik kimaradtak.
Karakterkódolás
Szöveges protokoll lévén az IRC esetén fontos az üzenetek megfelelő ábrázolása. Míg a bada Unicode stringeket használ, hálózaton keresztül gyakrabban kerül elő például az UTF-8 és az ASCII kódolás. Szerencsére az átalakítás fájdalommentes. Az Osp::Text névtér öt karakterkódolást biztosít, tételesen a GSM ABC, az ASCII, ISO8859-1, UCS-2 és az UTF-8 kódolások érhetőek el a megfelelő Encoding osztályon keresztül. A közös absztrakt ősosztály segít a konkrét kódolás elrejtésében, a használata pedig többféleképpen lehetséges, a szerintem legegyszerűbbet megmutatom példán.
// IrcSessionPrivate.h
class SessionPrivate : /* ... */
{
// ...
public:
result __SendMessage(const Osp::Base::String& message);
private:
Osp::Text::Encoding *__pEncoding;
// ...
}
// IrcSessionPrivate.cpp
result
SessionPrivate::__SendMessage(const Osp::Base::String &message)
{
Osp::Base::String msg = message;
// messages must be terminated with CRLF
msg.Append('\r');
msg.Append('\n');
AppLog("Sending message: \"%S\"", msg.GetPointer());
result r;
Osp::Base::ByteBuffer *buffer = __pEncoding->GetBytesN(msg);
r = GetLastResult();
TryCatch(r == E_SUCCESS, delete buffer, "GetBytesN failed [%s]", GetErrorMessage(r));
r = __pSocket->Send(*buffer);
delete buffer;
CATCH:
return r;
}
Látható, hogy a GetBytesN() metódus egy ByteBufferrel tér vissza, és mivel N utótagot kapott, nekünk kell biztosítani a puffer felszabadítását. Más metódusokkal mindez két lépéssel végezhető el — akár megadhatjuk mi is a végeredményt tároló puffert.
A kész üzenet elküldése is itt történik meg, amiben semmi mágia nincs: a Send() hatására az adat bekerül a TCP socket belső pufferébe, és amint lehetséges — Nagle algoritmus —, átmegy a hálózaton, más dolgunk nincs.
A fogadás problémája és a ByteBuffer
Az interneten terjedő példakódok a lehető legegyszerűbben oldják meg a bejövő adat fogadását: az OnSocketReadyToRecieve() eseménykezelőben egy Ioctl() hívás segítségével lekérdezik a beolvasható byte-ok számát, létrehoznak egy ekkora ByteBuffert, teleolvassák és kész./p>
Sajnos ez a megoldás a valóságban pazarló — folyamatos heapen foglalás és felszabadítás — a SecureSocketek esetén egyáltalán nem is használható, továbbá nem is biztos, hogy helyes viselkedést eredményez. Ugyanis előfordulhat, hogy egy hosszabb üzenet két darabban érkezik meg, ekkor inkonzisztens állapot lép fel, ha teszünk extra erőfeszítéseket az üzenetek összevárására.
Pedig nem kell messzire menni, a ByteBuffer sokoldalúbb, mint első ránézésre tűnhet. A ByteBuffer ugyanis nem egyszerű byte-tömb — bár annak is használható; a mark, limit és aktuális pozíció attribútumokkal sok problémát lehet egyszerűen megoldani. Az ábrán látható ezen értékek egymással való kapcsolata. A framework függvényei tiszteletben tartják a korlátokat, így lehet automatizálni néhány folyamatot.
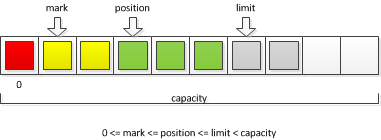
A pozíció és az opcionális limit határozza meg egy művelet intervallumát: [pozíció; limit), illetve [pozíció; kapacitás), ha nincs limit beállítva. Egy gyakorlati példa a socketről beolvasott UTF-8 adat Stringgé alakítása, melyet mindjárt megmutatok.
A mark segítségével a puffer alsó területét lehet megvédeni, a pozíció ennél lejjebb nem mehet — kivéve ha explicite oda állítjuk. Erre nem volt szükség a kódomban eddig, de biztosan hasznosítható.
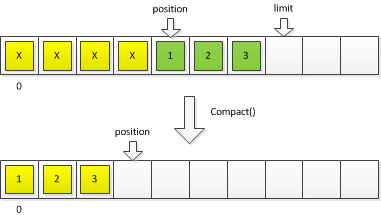
Két fontos és praktikus metódust emelnék ki a ByteBuffer lehetőségeiből: a Flip() és a Compact() hívást. Az előbbi gyakran előkerül a socketes példakódokban, egy félig olvasott pufferből könnyen behatárolható vele a hasznos adatot tartalmazó rész.

A Compact() segítségével a puffer eleje eldobható, megőrizve a jelenlegi pozíció és a limit közötti adatot, majd azonnal folytatható például egy beolvasás. Ezt ki is használom a sorok összevárásához.
Az én megoldásom
Az előző eszközökkel és minimális gondolkodással összerakható egy olyan fogadó metódus, mely bár nem tökéletes — ezt a cikk írása közben vettem észre — de az előző problémát elkerüli.
Először a csomagonként létrehozott puffer helyett egy példány kell csak, a SessionPrivate tagváltozójaként, kellően nagy kapacitással — ennek túlcsordulása a problémás, beblokkolhatja a bejövő irányt, de nagyobb vészt a belső ellenőrzések miatt nem okozhat.
A beolvasás mindig az aktuális pozíciótól történik — ezt a framework automatikusan így végzi —, melyet explicite nem állítok alaphelyzetbe. Helyette az olvasás után megkeresem a legutolsó \n karaktert, a limit segítségével feldolgozom az akár több teljes sort, majd a Compact() segítségével előkészítem a következő olvasást. A puffer állapotát ez alatt a következő ábra mutatja be.
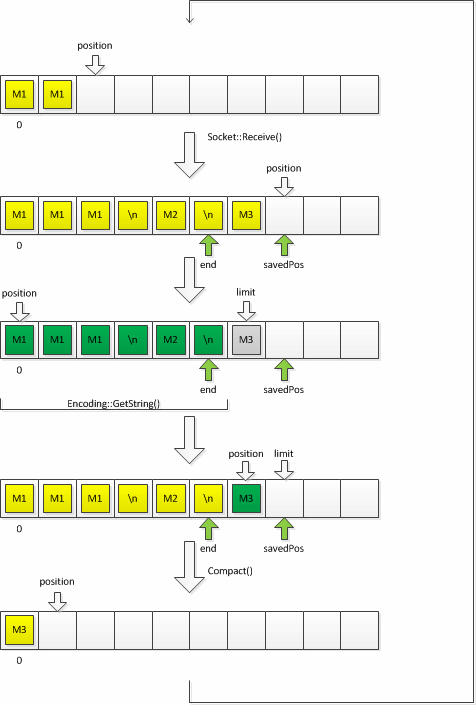
És a forráskódrészlet:
SessionPrivate::OnIrcSocketReadyToReceive(SocketWrapper &socket)
{
AppLog(__PRETTY_FUNCTION__);
result r = socket.Receive(__buffer);
if (r == E_SUCCESS)
{
int end;
result findres = Utility::FindLastNewLineLimit(__buffer, end);
if (findres == E_SUCCESS)
{
int savedPos = __buffer.GetPosition();
__buffer.SetLimit(end);
__buffer.SetPosition(0);
Osp::Base::String str;
__pEncoding->GetString(__buffer, str);
DispatchMessages(str);
__buffer.SetPosition(end);
__buffer.SetLimit(savedPos);
__buffer.Compact();
}
else
{
// no complete messages found
// position is at the end -> do nothing
}
}
}
Karma




